
Excelで管理している売上データの分析をChatGPTに丸投げしてみた
tsukasa
Ainova

かつて専門的なプログラミング知識が必須だったデータ分析の世界は、ChatGPTのような先進的なAIの登場により、大きな変革期を迎えています。
特に、ChatGPTの「Advanced Data Analysis(旧Code Interpreter)」機能をはじめとする多様な能力は、データサイエンティストの業務効率を劇的に向上させる可能性を秘めています 。
本記事では、2025年の最新情報を踏まえ、データサイエンティストがChatGPTを最大限に活用し、データ収集・前処理から高度な分析、モデル構築、そして結果の解釈と報告に至るまで、ワークフロー全体をいかに効率化し、生産性を爆発的に向上させることができるか、具体的な手順や高度なテクニック、さらには導入時の注意点までを網羅的に解説します。
ChatGPTは、単なる質疑応答ツールから、データサイエンス業務を強力に支援する多機能プラットフォームへと進化を遂げています。
特に有料プランで提供される「Advanced Data Analysis (旧称:Code Interpreter)」機能は、ChatGPT上で直接Pythonコードの実行やファイルのアップロード・ダウンロードを可能にし、データサイエンティストの作業スタイルに革命をもたらしました。
CSVやExcelなどのデータをチャットインターフェースを通じて簡単に取り込み、そのデータに対してPythonコードを自動で実行・分析し、グラフ作成まで一任できるようになったのです。
2025年現在、この進化はさらに加速しています。
これらの進化により、データサイエンティストは、ルーチンワークの自動化に留まらず、より複雑な問題解決や新たな洞察の発見に注力できるようになっています。

データサイエンティストの業務において、コーディングは依然として中核的なスキルです。
ChatGPTは、このコーディング作業のあらゆる側面で、生産性を飛躍的に向上させる能力を備えています。
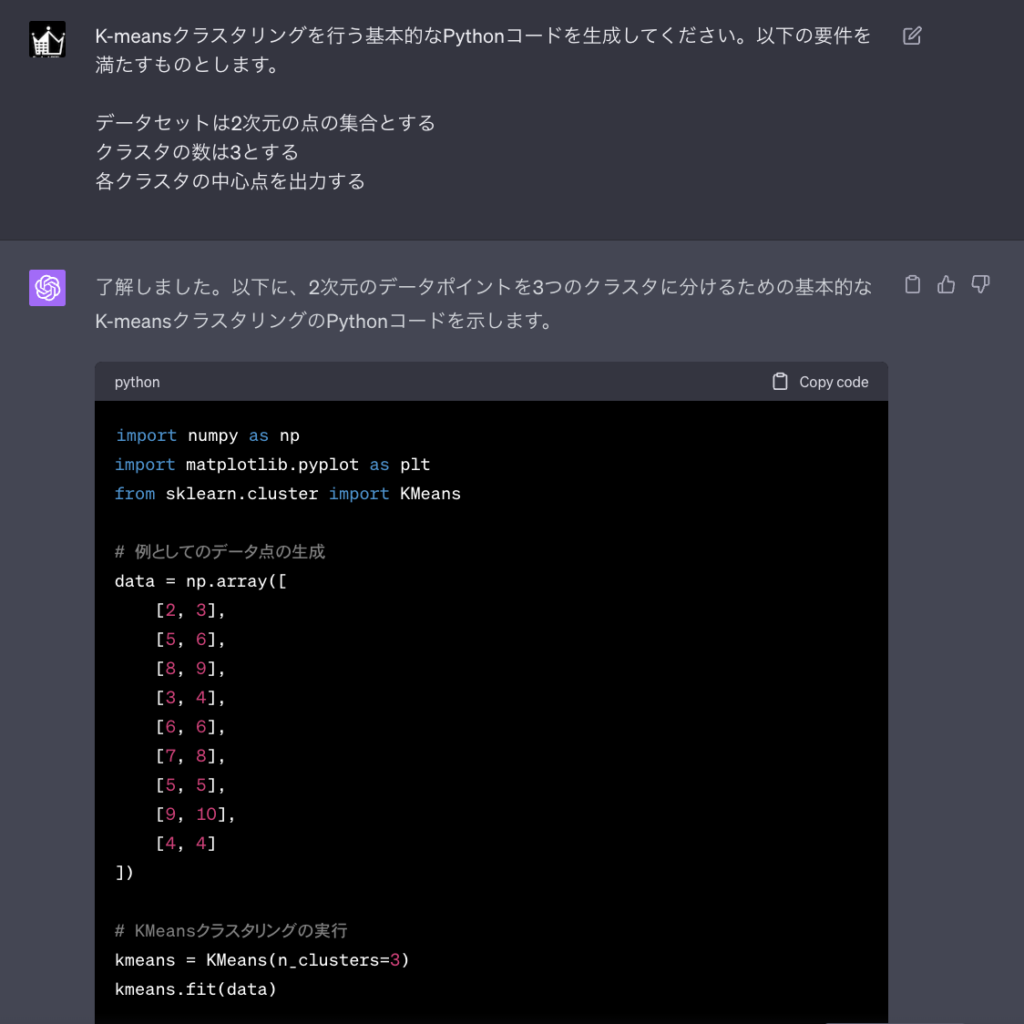
ChatGPT、特にo1-miniのようなコーディング特化モデルは、指定した条件や要件に基づき、Python、R、SQLなど多様なプログラミング言語で最適なコードを自動生成します。
実装したいアルゴリズム、特定のデータ処理ロジック、あるいは分析パイプライン全体の骨子を自然言語で伝えるだけで、高品質なサンプルコードや実行可能なスクリプトを迅速に入手できます。
これにより、データサイエンティストはゼロからのコーディング時間を大幅に削減し、より本質的な分析設計やモデルの改善に集中できます。
2025年には、ソフトウェア開発に特化したモデルが登場し、Pull Request形式でのコード提案や反復テストによる信頼性向上も期待されています。

ChatGPTは、自身が生成したコードだけでなく、既存のコードに対するレビューも実行できます。分析コードにおける小さなバグや処理の非効率性は、分析結果に重大な影響を及ぼす可能性があります。
AIによる客観的かつ網羅的なレビューは、コードの品質を担保する上で非常に有効です。具体的には、構文エラーの指摘、ロジックの矛盾点の発見、パフォーマンス改善のための提案、さらにはセキュリティ脆弱性に関するアドバイスも期待できます。
また、エラーメッセージやスタックトレースをChatGPTに提示することで、原因の特定や修正案の提示といったデバッグ作業の強力なサポートを得られます。
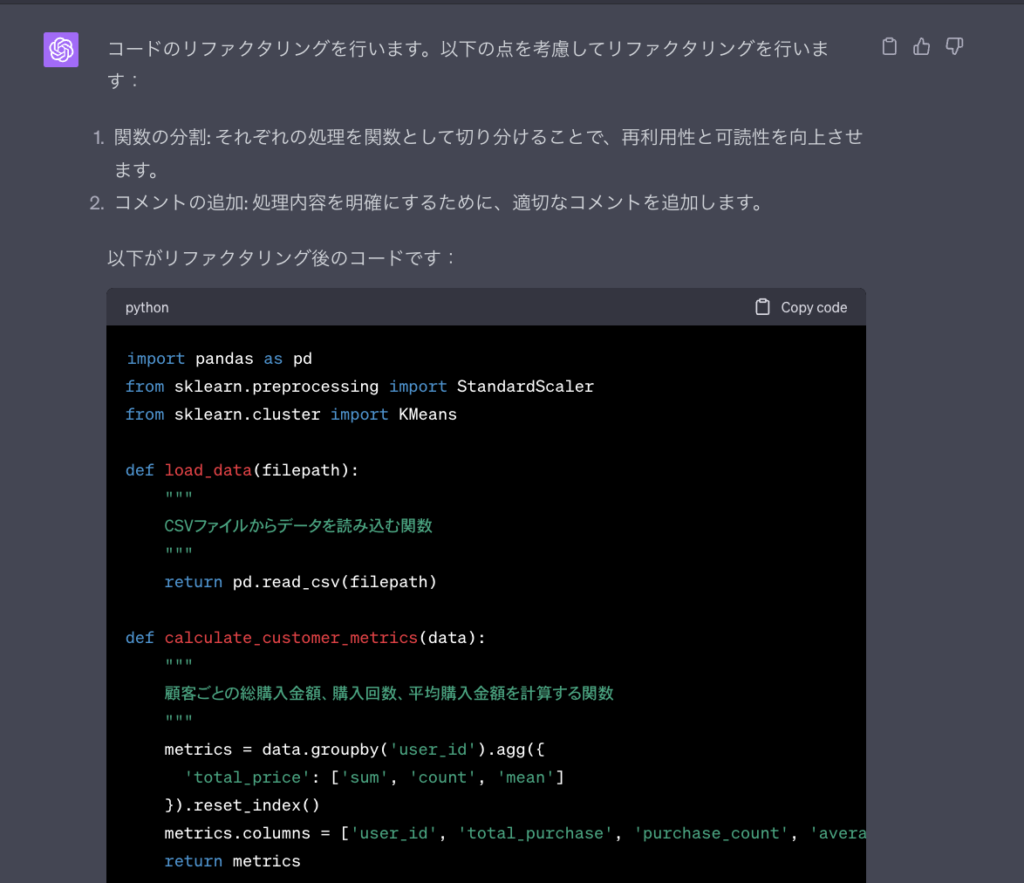
データ分析プロジェクト、特に探索的データ分析や機械学習モデル開発の過程では、試行錯誤が繰り返されるため、コードが複雑化・煩雑化しやすい傾向にあります。
ChatGPTは、このような複雑なコードをよりクリーンで効率的、かつシンプルな構造に整理するためのリファクタリング案を提案します。
可読性の低い部分の改善、冗長な処理の排除、再利用可能な関数の抽出などを支援し、結果としてメンテナンス性が高く、他の開発者にも理解しやすいコードベースの構築に貢献します。

「Advanced Data Analysis」機能やAPI連携を活用することで、ソースコードを基にした技術ドキュメント(関数ごとのdocstring、クラスの説明、モジュールの概要、READMEファイルなど)の自動生成が可能です。
ソースコードをアップロードし、「この関数のドキュメントをマークダウン形式で作成して」といった簡単な指示を与えるだけで、構造化されたドキュメントが出力されます。
特定のフォーマットや記述ルール(例:Googleスタイルdocstring)を指定することも可能で、従来非常に時間のかかっていたドキュメンテーション作業を大幅に効率化できます。

もちろん、出力形式を指定すれば、ドキュメント作成のルールがある場合にはそのルールを指定すればその形式に沿ったドキュメントを作成してくれます。
ChatGPTは、データ分析の各フェーズにおいて、データサイエンティストの強力なパートナーとなり、ワークフロー全体の効率化と高度化を実現します。
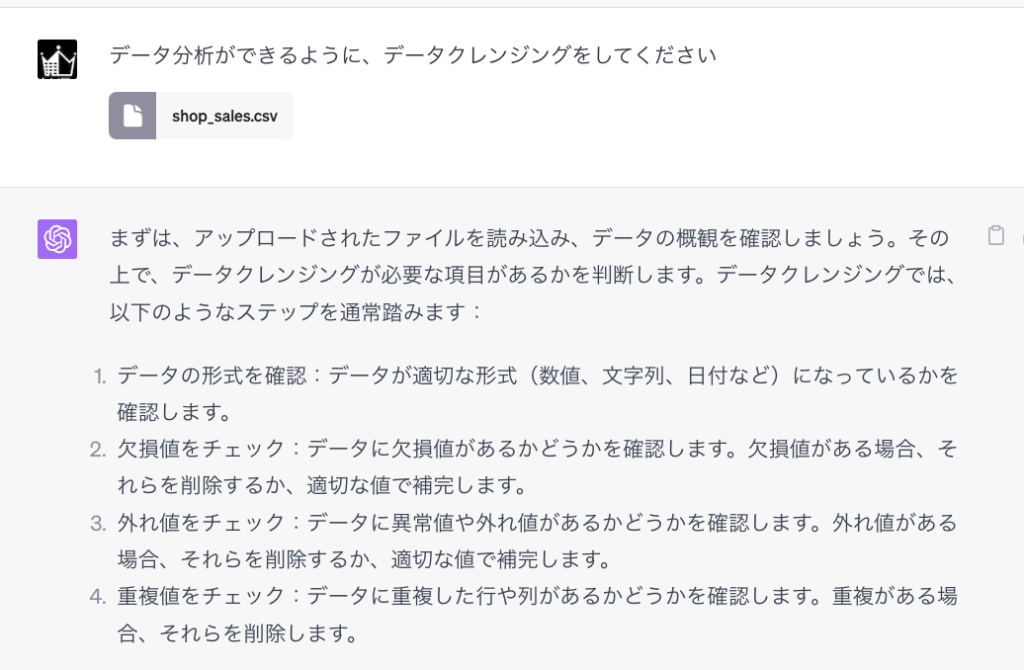
ChatGPTの「Code interpreter」を使えば、分析したいデータをアップロードして、簡単な指示を出すだけで、Code interpreterが自動でデータクレンジングを行ってくれます
具体的な指示やデータについての情報を与えなくても、データを確認しながら、欠損値や異常値のチェックや、日時データの形式を整えたり、重複行を削除したりしてくれます。
あらかじめどのようなクレンジングを行いたいかが決まっている場合は、具体的に指示すれば、それに合わせたクレンジングも行ってくれます。
これにより、データクレンジングのような必要だけど自分でやらなくても良い作業は「Code interpreter」に任せて、自分はより重要な作業に時間を使うことができますね。


ChatGPTの「Code interpreter」を使えば、さまざまな形式のダミーデータ作成も一瞬で完了します。
ダミーデータの作成は各カラムの条件を指定したり、データが不自然に見えないように設計したりと意外と手間のかかる作業ですが、ChatGPTを使えばこの作業が一瞬で完了します。
一度作成してもらったダミーデータについても、「これはこうしたい」というフィードバックを即座に反映してくれるので、まるで会話をしているかのように、必要なダミーデータを作成することができます。
また、作成したダミーデータはCSV形式で出力可能なので、すぐに利用することができます。

事前情報を提供しなくても、データをアップロードするだけで、そのデータの特性を把握し、必要な基礎集計を自動で行ってくれます。

今回はPOSデータをアップロードしたため自動的に商品カテゴリごとの集計を行ってくれましたが、これが顧客データであれば年齢層や性別、地域ごとの集計をやってくれますし、製品レビューデータであれば評価スコアの平均や分布というようにデータの特徴に合った基礎集計を行ってくれます。
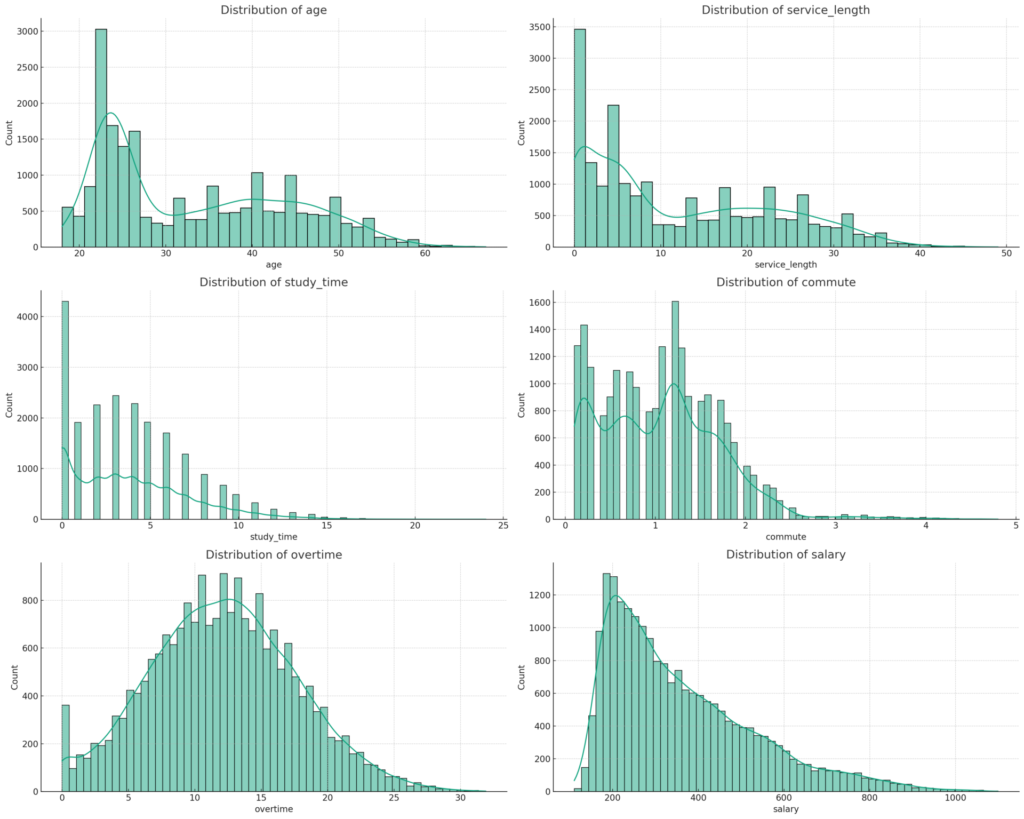
さらに、データを視覚的に理解するための可視化も素早く行ってくれます。
各変数同士の相関など見たいものがあるときは「各変数の相関を見たいをといった要望を伝えるだけで、コードを1行も書くことなくデータの概要を把握することができます。
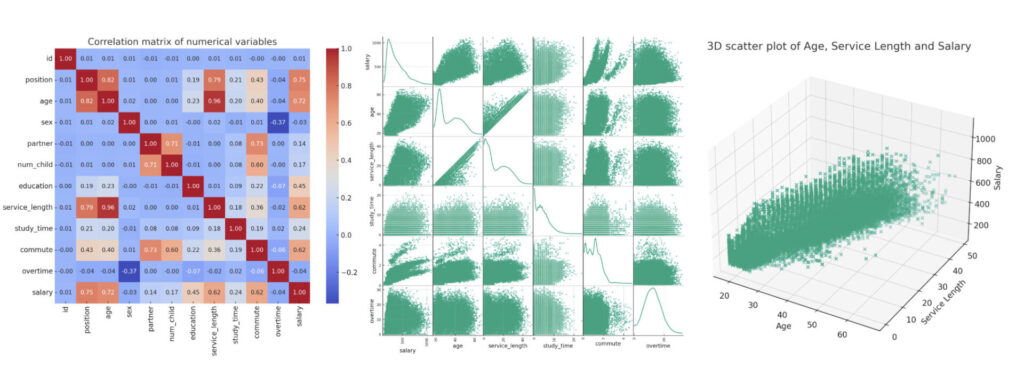
「Code interpreter」はデータの可視化も非常に得意です。
自分でコードを書いてデータを見やすく可視化しようとすると、色の調整やタイトルの付け方など、面倒な作業が伴います。
しかし、「Code interpreter」を使えば具体的な指示をしなくても、コードを1行も書かなくても自動で見やすい可視化も行ってくれます。
なので、データの理解のための可視化はもちろんのこと、レポートやプレゼンテーション資料用の見やすいグラフ作成をお願いすることで、資料作成もぐっと楽になります。

具体的な分析手順を示さなくても、分析したい内容だけを伝えるれば、その内容通りの分析を「Code interpreter」が考えて実行してくれます

さらに、ただ分析を行うだけでなく、その結果に基づいて考察し戦略まで考えてもらうことも可能です。
データサイエンティストであれば、自分で分析を行った方がより精度の高い結果が得られることは間違いありませんが、基礎集計の結果を確認したり、分析の流れや手法を参考にするには十分なレベルの分析を行ってくれます。
また、単純な分析であれば、「Code interpreter」に任せることで、自身はより複雑な分析に専念できます。
実際に、アパレルの売上データを使った分析を、「Code interpreter」に丸投げしてみたところ、期待以上の結果が得られました。
詳細は以下の記事でまとめているので、興味がある人はこちらもご覧ください。


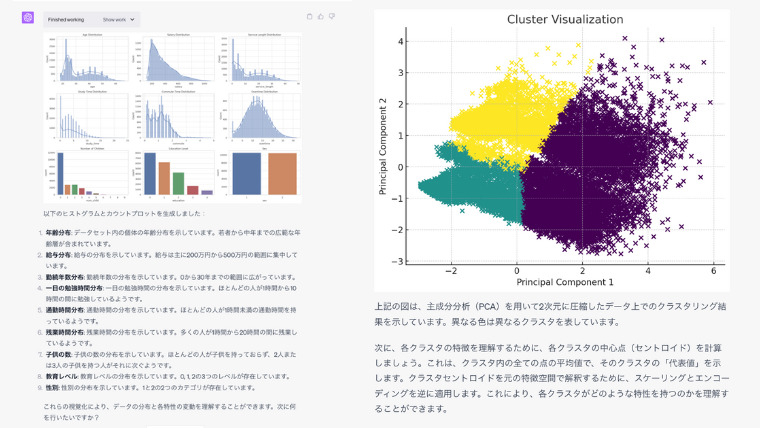
「Code interpreter」は簡単な指示だけで主成分分析(PCA)からクラスタリング、クラスタリング結果の可視化まで全て自動で行ってくれます。
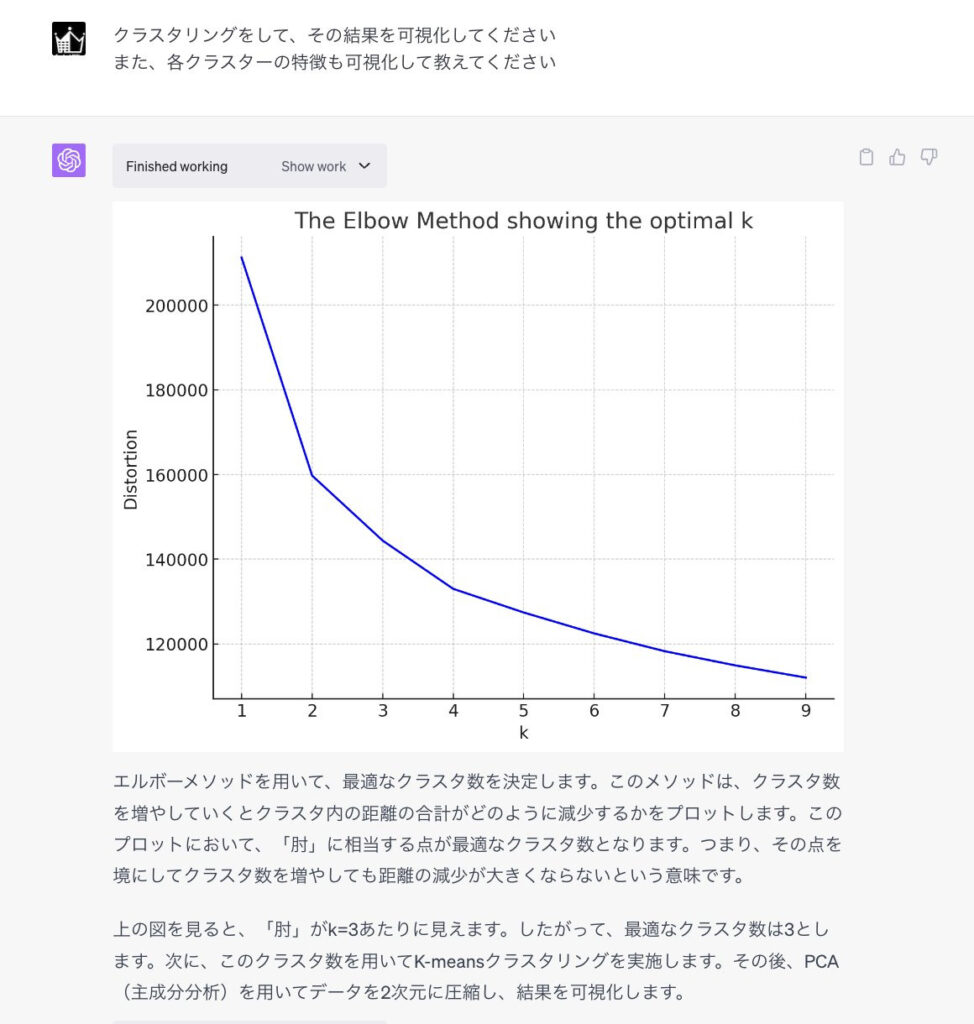
特に指示を出さなくても、データを読み込んだ時点で最適なクラスタ数をエルボー法に基づいて判断してくれます。

さらに、各クラスタの特徴を詳しく分析し、それぞれのクラスタがどのような性質を持つのか、何を表しているのかを明確に説明してくれます。
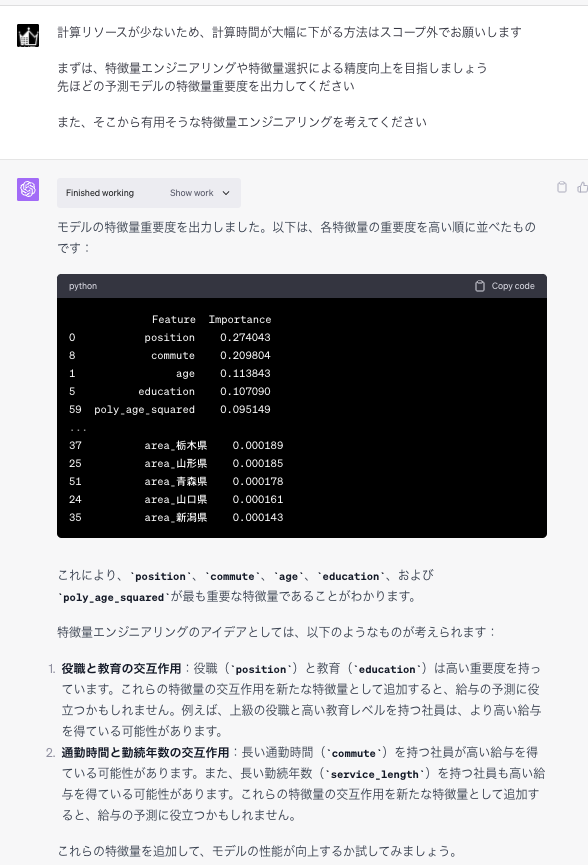
「Code interpreter」を使えば簡単な予測モデルの作成も可能です。
まだ、直接実用化できるレベルのモデルを作成することは難しいですがが、基本的な予測モデルの構築と、それらの特徴量の重要度を評価するには充分活用できます。
さらに、モデル作成の過程で基礎的な分析を行ったり、目的変数と説明変数の相関関係を調べてくれるので、自分で予測モデルを作るための参考にすることも可能です。
実際に「Code interpreter」を使って、どのくらいの予測モデルが作れるかも検証してみたので、興味がある人は以下の記事も参考にしてください。

データサイエンティストがCode interpreterを上手に使うには、まずはCode interpreterが得意なタスクとと苦手なタスクを理解して、得意なタスクのみに集中して作業をしてもらうことです。
Code interpreterはデータ理解の能力が高いため、基礎分析をしてデータの特徴について解説してもらうことができます。
データの可視化も得意なので、本格的な分析を始める前に、データをCode interpreterに渡すことで、基本的な分析と可視化を一手に引き受けてもらうことができます
また、コーディング能力も高いので、誰がやっても変わらないようなコーディングタスク(例えばダミーデータの生成など)を任せることができます。これにより、自分自身はより生産的な他のタスクに集中することができます。
さらに、自分が書いたコードのレビューやリファクタリングを依頼することも可能です。これにより、より効率的かつ正確なコードを作成する手助けを受けることができます。
以上のような方法で、Code interpreterの能力を最大限に活用することで、データ分析の効率を大幅に向上させることが可能となります。
その一方で、Code interpreterには苦手なタスクもあります
Code interpreterの実行環境にはメモリや容量に制限があるため、ハイパーパラメータの調整や、ビッグデータの解析、深層学習などはほとんどできません。
また、外部との接続もできないので、データベースに直接繋いで分析をしたり、外部APIにリクエストを送信したり、Webスクレイピングを行ったりすることはできません。
これらの理由により、高度な分析や実用レベルの予測モデルの作成は現時点では不向きです。
こちらの記事は、GMOインターネットグループの技術ブログに掲載されたもので、ChatGPTのAPIとLangChainを活用し、「全自動データ分析ツール」を作成できるかどうかを検証しています。
この記事では、アリババが発表した「ChatGPTがデータ分析者としてどれほど優れているか」を評価した論文をベースに、生成AIを組み込んだデータ分析アプリを試作しています。
作成されたアプリ自体は簡易的なものですが、実装手順が非常に詳しく、わかりやすく解説されているため、「生成AIを活用したデータ分析アプリを作ってみたい」と考えている方には非常に参考になる内容となっています。
こちらの記事も、ChatGPTのAPIとLangChainを使って、全自動分析ツールを作れるかを試した記事ですが、データ分析の専門会社であるブレインパッドが作っているだけ会ってより本格的なツールを作っています。
分析ツールが実際に動いているデモ画面もGIFで確認できるので、ChatGPTを使えばどんな全自動分析ツールが作れるか知りたい人は必見です。
こちらの記事も、ChatGPTのAPIとLangChainを使ってデータ分析ツールを作った話です。
この分析ツールの特徴は、データ分析をスムーズに行うために、「プランナーAI」や」「コードAI」、「レビューAI」など6つの機能に分けて実装している点です。
また、開発も1週間程度で行ったとのことで、ChatGPTのAPIやLangChainを使えばサクッと自動分析ツールが作れる良い例ですね。
上の記事と同じくChatGPTの「Code Interpreter」を使って、アパレル店舗の売り上げデータを分析している記事です。
多くの企業で取り組んでいるであろう売上分析をChatGPTの「Code Interpreter」を使えばどれくらい任せられるのかが解説されています。
売上分析をしたいと思っているけど、分析に人員を割くのは難しい小売店などで活用できるようになるのではと思わせてくれます。
ChatGPTの強力な機能を活用する一方で、その導入と運用には慎重な検討と倫理的な配慮が不可欠です。
機密性の高い企業データや個人情報をパブリックなChatGPTに入力することは、情報漏洩のリスクを伴います。
API利用時のAPIキーの厳重な管理、送受信データの暗号化はもちろんのこと、可能であればAzure OpenAI ServiceやChatGPT Enterpriseのようなセキュリティが強化されたエンタープライズ向けソリューションの検討が重要です。
また、社内で明確なデータ取り扱いガイドライン(入力して良い情報、禁止する情報の区分など)を策定し、従業員教育を徹底することが不可欠です。
LLMは、もっともらしい誤情報を生成する「ハルシネーション」を起こす可能性があります。
データサイエンスの文脈では、これが誤った分析結果や意思決定につながるリスクがあるため、対策が必須です。
具体的で明確なプロンプトの使用、RAGによる事実に基づいた応答生成、生成された情報(特にコードや分析結果)の人間による相互検証、そしてフィードバックループの確立などが有効です。
学習データに内在するバイアスがAIの出力に反映され、不公平な分析結果を生み出す可能性に留意する必要があります。
また、AIが生成したコードやレポートの著作権の取り扱いについても、社内でルールを明確化しておく必要があります。個人情報保護法(GDPRやCCPAなど)や、2024年8月に施行されたEUのAI規制法のような、進化する法的枠組みを常に把握し、遵守することが求められます。
本記事で見てきたように、ChatGPTは2025年現在、データサイエンティストのあらゆる業務において、生産性を劇的に向上させるポテンシャルを秘めています。
コード生成、データ分析、レポート作成といった具体的なタスクの効率化はもちろん、API連携やカスタムGPTs、AIエージェントといった高度な活用により、これまで不可能だったレベルの自動化や特化型分析も視野に入ってきます。
データサイエンティストの仕事がAIに奪われるというよりは、AIを強力なアシスタントとして使いこなし、より高度で創造的な業務にシフトしていく時代と言えるでしょう。
そのためには、データサイエンティスト自身も進化し続ける必要があります。最新機能の学習意欲、プロンプトエンジニアリングスキルの研鑽、そして何よりもセキュリティや倫理に関する高い意識を持ち、責任ある利用を心がけることが不可欠です。
ChatGPTは強力なツールですが、最終的な判断や分析の妥当性を保証するのは人間の専門知識、批判的思考、そして倫理観です。
AIとの協調を通じて、データサイエンティストはこれまでにないレベルの洞察と価値を創出し、データ駆動型の未来を力強く切り拓いていくことになるでしょう。


